
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Posts
portfolio
Dynamic Execution of CNNs on a Cortex-M7 MCU using BLE
In this demonstration, we show how two CNNs trained on different tasks can be sent via BLE to a Nicla Vision MCU (Cortex-M7) and then executed on the device. This can be done without flashing or resetting the MCU at runtime by dynamically reconfiguring the CNN running on the MCU based on the information received via BLE. Both the topography of the CNN and its weights can be adjusted this way within in the resource constraints of the MCU.
Keyword Spotting
This demonstration shows a deep neural network running on an Arduino Nano 33 BLE Sense microcontroller performing keyword spotting. The DNN can distinguish 36 different spoken keywords (Pete Warden’s Speech Commands dataset), infers at about 800ms per 1 second audio sample, and requires 190KB of ROM and 111KB of RAM.
On-Device DNN Training
Demo of on-device DNN training of an animal classification dataset with 10 classes on a STM32H743VI ARM Cortex-M7 microcontroller (OpenMV H7 R2).
MicroYOLO Person Detection
Demo of MicroYOLO person detection on a STM32H743VI ARM Cortex-M7 based microcontroller (OpenMV H7 R2).
publications
Energy-efficient Deployment of Deep Learning Applications on Cortex-M based Microcontrollers using Deep Compression
Published in MBMV; 26th Workshop, 2023
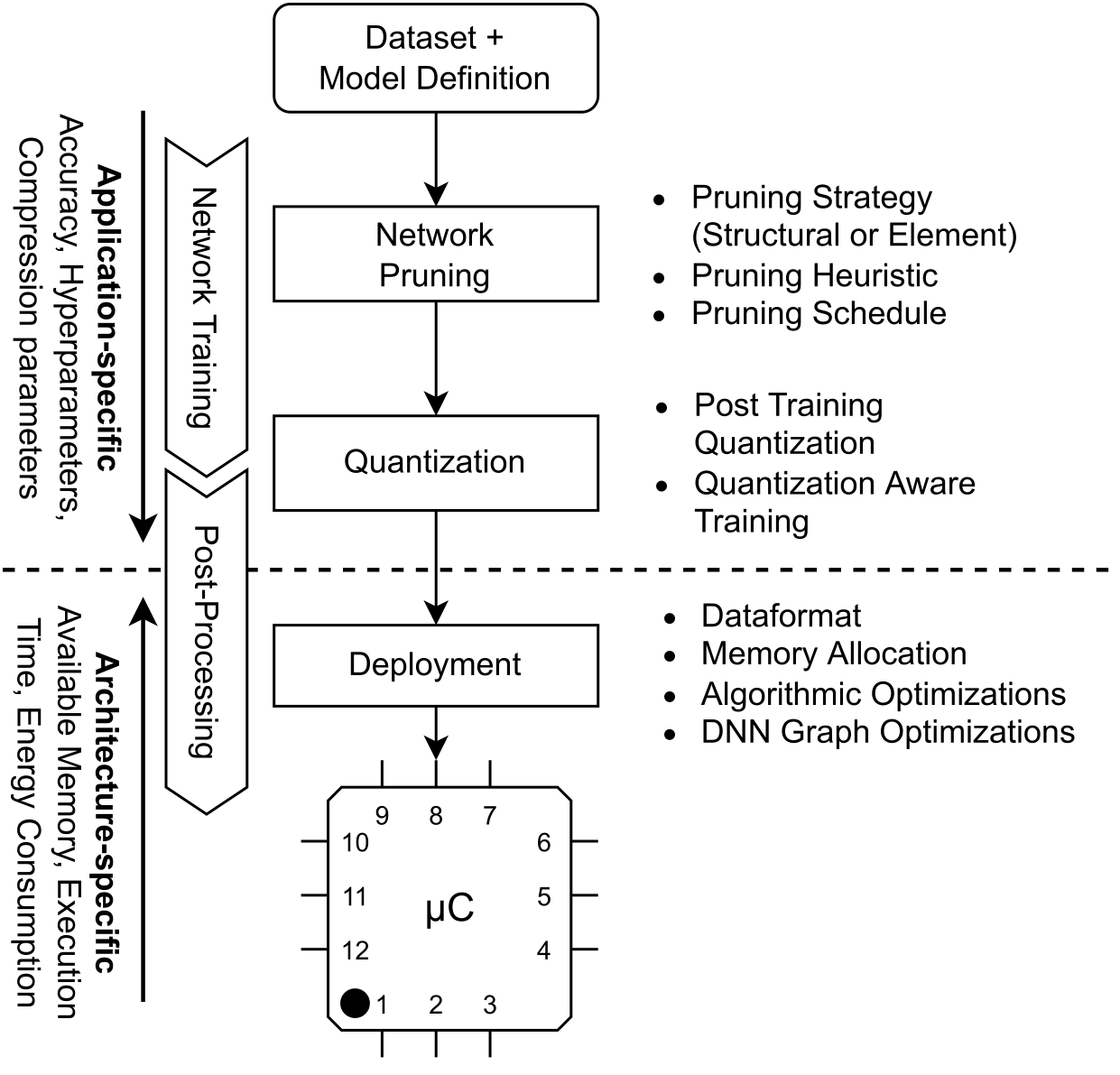
Large Deep Neural Networks (DNNs) are the backbone of today’s artificial intelligence due to their ability to make accurate predictions when being trained on huge datasets. With advancing technologies, such as the Internet of Things, interpreting large quantities of data generated by sensors is becoming an increasingly important task. However, in many applications not only the predictive performance but also the energy consumption of deep learning models is of major interest. This paper investigates the efficient deployment of deep learning models on resource-constrained microcontroller architectures via network compression. We present a methodology for the systematic exploration of different DNN pruning, quantization, and deployment strategies, targeting different ARM Cortex-M based low-power systems. The exploration allows to analyze trade-offs between key metrics such as accuracy, memory consumption, execution time, and power consumption. We discuss experimental results on three different DNN architectures and show that we can compress them to below 10% of their original parameter count before their predictive quality decreases. This also allows us to deploy and evaluate them on Cortex-M based microcontrollers.
Recommended citation: Deutel, M., Woller, P., Mutschler, C., & Teich, J. (2023, March). Energy-efficient Deployment of Deep Learning Applications on Cortex-M based Microcontrollers using Deep Compression. In MBMV 2023; 26th Workshop (pp. 1-12). VDE.
Download Paper | Download Paper (open) | Download Slides
microYOLO: Towards Single-Shot Object Detection on Microcontrollers
Published in ECML PKDD Conference, at the 4th Workshop on IoT, Edge, and Mobile for Embedded Machine Learning, 2023
This work-in-progress paper presents results on the feasibility of single-shot object detection on microcontrollers using YOLO. Single-shot object detectors like YOLO are widely used, however due to their complexity mainly on larger GPU-based platforms. We present microYOLO, which can be used on Cortex-M based microcontrollers, such as the OpenMV H7 R2, achieving about 3.5 FPS when classifying 128x128 RGB images while using less than 800 KB Flash and less than 350 KB RAM. Furthermore, we share experimental results for three different object detection tasks, analyzing the accuracy of microYOLO on them.
Recommended citation: Deutel, M., Mutschler, C., & Teich, J. (2023). microYOLO: Towards Single-Shot Object Detection on Microcontrollers. In ECML PKDD Conference 2023, at the 4th Workshop on IoT, Edge, and Mobile for Embedded Machine Learning.
Download Paper | Download Paper (open) | Download Slides
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
Published in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024
On-device training of DNNs allows models to adapt and fine-tune to newly collected data or changing domains while deployed on microcontroller units (MCUs). However, DNN training is a resource-intensive task, making the implementation and execution of DNN training algorithms on MCUs challenging due to low processor speeds, constrained throughput, limited floating-point support, and memory constraints. In this work, we explore on-device training DNNs for different sized Cortex-M MCUs (Cortex-M0+, Cortex-M4, and Cortex-M7). We present a method that enables efficient training of DNNs completely in place on the MCU using fully quantized training (FQT) and dynamic partial gradient updates. We demonstrate the feasibility of our approach on multiple vision and time-series datasets and provide insights into the tradeoff between training accuracy, memory overhead, energy, and latency on real hardware. The results show that compared to related work, our approach requires 34.8% less memory and has a 49.0% lower latency per training sample, with dynamic partial gradient updates allowing a speedup of up to 8.7 compared to fully updating all weights.
Recommended citation: Deutel, M., Hannig, F., Mutschler, C., & Teich, J. (2024). On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers, in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems.
Download Paper | Download Paper (open)
Energy-Efficient AI on the Edge
Published in Unlocking Artificial Intelligence pp 359 - 380, Springer Link, 2024
This chapter shows methods for the resource-optimized design of AI functionality for edge devices powered by microprocessors or microcontrollers. The goal is to identify Pareto-optimal solutions that satisfy both resource restrictions (energy and memory) and AI performance. To accelerate the design of energyefficient classical machine learning pipelines, an AutoML tool based on evolutionary algorithms is presented, which uses an energy prediction model from assembly instructions (prediction accuracy 3.1%) to integrate the energy demand into a multiobjective optimization approach. For the deployment of deep neural network-based AI models, deep compression methods are exploited in an efficient design space exploration technique based on reinforcement learning. The resulting DNNs can be executed with a self-developed runtime for embedded devices (dnnruntime), which is benchmarked using the MLPerf Tiny benchmark. The developed methods shall enable the fast development of AI functions for the edge by providing AutoML-like solutions for classical as well as for deep learning. The developed workflows shall narrow the gap between data scientist and hardware engineers to realize working applications. By iteratively applying the presented methods during the development process, edge AI systems could be realized with minimized project risks.
Recommended citation: Witt, N., Deutel, M., Schubert, J., Sobel, C., Woller, P. (2024). Energy-Efficient AI on the Edge. In: Mutschler, C., Münzenmayer, C., Uhlmann, N., Martin, A. (eds) Unlocking Artificial Intelligence. Springer, Cham.
Download Paper
Fused-Layer CNNs for Memory-Efficient Inference on Microcontrollers
Published in Workshop on Machine Learning and Compression @ NeurIPS, 2024

Convolutional Neural Networks (CNNs) have been established as the dominant approach to computer vision tasks. As a result, efficient inference of CNNs has become a major concern to enable the processing of image data close to where it is generated by camera sensors, most commonly microcontroller units (MCUs). However, major obstacles to deploying CNNs on MCUs are the strict memory and bandwidth constraints that make processing high-resolution images on many MCUs infeasible. In this work, we propose a method to fuse convolutional layers in quantized CNNs, which can serve as an additional dimension for optimizing the memory requirements of CNNs during inference. By fusing memory-intensive convolutions in the early inverted residual blocks of MobileNetv2-like CNNs, we show that memory requirements during inference can be reduced by up to 54% at the cost of only about a 14% increase in latency and no change in accuracy. As an example, we show that this reduction enables the deployment of image processing pipelines on a Cortex-M7 MCU that supports image resolutions up to 320x320 pixels compared to the 128x128 pixels resolution commonly used in related work.
Recommended citation: Deutel, M., Hannig F., Mutschler, C., & Teich, J. (2024). Fused-Layer CNNs for Memory-Efficient Inference on Microcontrollers. In Workshop on Machine Learning and Compression @ NeurIPS.
Download Paper
Combining Multi-Objective Bayesian Optimization with Reinforcement Learning for TinyML
Published in ACM Transactions on Evolutionary Learning and Optimization, 2025
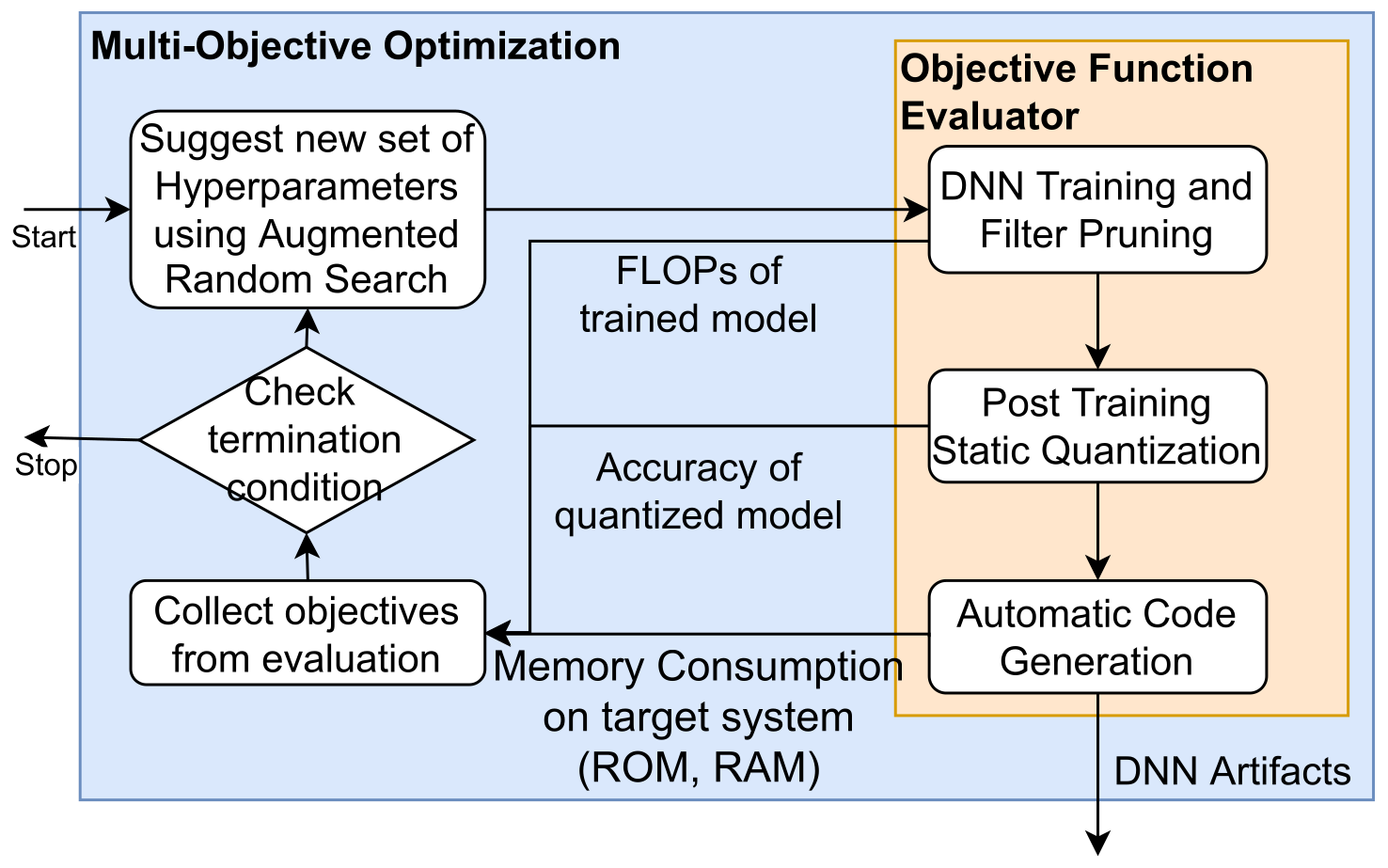
Deploying deep neural networks (DNNs) on microcontrollers (TinyML) is a common trend to process the increasing amount of sensor data generated at the edge, but in practice, resource and latency constraints make it difficult to find optimal DNN candidates. Neural architecture search (NAS) is an excellent approach to automate this search and can easily be combined with DNN compression techniques commonly used in TinyML. However, many NAS techniques are not only computationally expensive, especially hyperparameter optimization (HPO), but also often focus on optimizing only a single objective, e.g., maximizing accuracy, without considering additional objectives such as memory requirements or computational complexity of a DNN, which are key to making deployment at the edge feasible. In this paper, we propose a novel NAS strategy for TinyML based on multi-objective Bayesian optimization (MOBOpt) and an ensemble of competing parametric policies trained using Augmented Random Search (ARS) reinforcement learning (RL) agents. Our methodology aims at efficiently finding tradeoffs between a DNN’s predictive accuracy, memory requirements on a given target system, and computational complexity. Our experiments show that we consistently outperform existing MOBOpt approaches on different datasets and architectures such as ResNet-18 and MobileNetV3.
Recommended citation: Deutel, M., Kontes, G., Mutschler, C., & Teich, J. (2025). Combining Multi-Objective Bayesian Optimization with Reinforcement Learning for TinyML. ACM Transactions on Evolutionary Learning and Optimization.
Download Paper | Download Paper (open)
Multi-Objective Bayesian Optimization with Reinforcement Learning for Edge Deployment of DNNs on Microcontrollers
Published in The Genetic and Evolutionary Computation Conference (GECCO), 2025
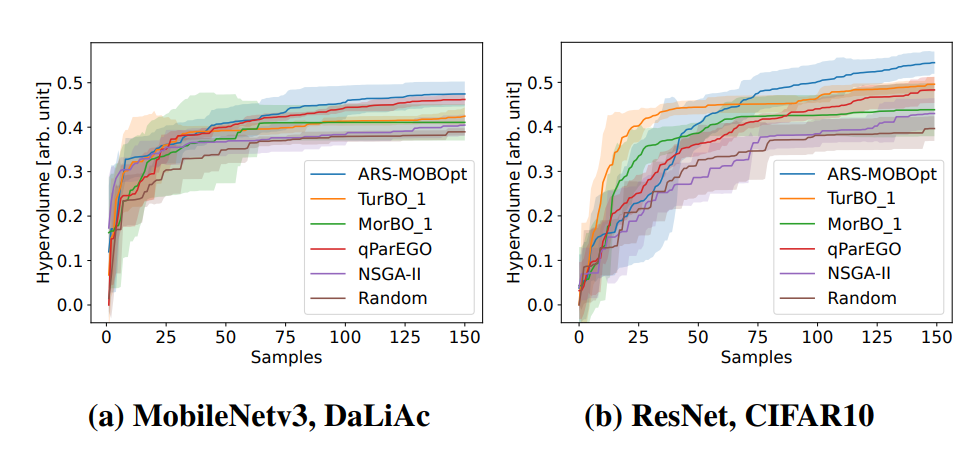
Deploying deep neural networks (DNNs) on microcontroller units (MCUs) is a common trend to process the increasing amount of sensor data generated at the edge, but it is challenging due to resource and latency constraints. Neural architecture search (NAS) helps automate the search for suitable DNNs. In our original work “Combining Multi-Objective Bayesian Optimization with Reinforcement Learning for TinyML”, we present a novel NAS strategy for edge deployment using multi-objective Bayesian optimization (MOBOpt) and reinforcement learning (RL). Our approach efficiently balances accuracy, memory, and computational complexity, outperforming existing methods on multiple datasets and architectures such as ResNet-18 and MobileNetV3.
Recommended citation: Deutel, M., Kontes, G., Mutschler, C., & Teich, J. (2025). Multi-Objective Bayesian Optimization with Reinforcement Learning for Edge Deployment of DNNs on Microcontrollers. The Genetic and Evolutionary Computation Conference (GECCO).
Download Paper | Download Slides
Early-Exit Neural Architecture Search for Energy-Harvesting Edge Computing
Published in IEEE 18th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), 2025
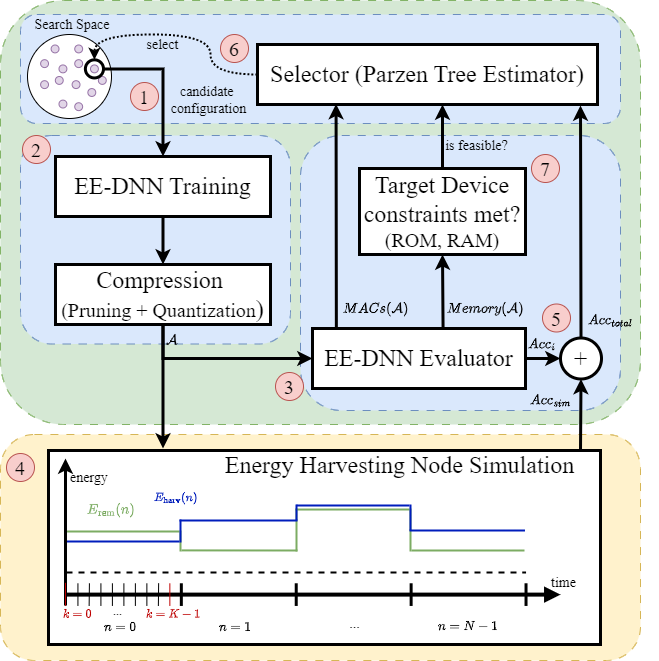
Energy harvesting (EH) is increasingly used in wireless sensor nodes to extend the lifetime of battery-powered devices in remote locations. On such devices, the use of deep neural networks (DNNs) is limited not only by the memory and computational constraints of the system, but also by the often large amount of energy required to perform DNN inference. As a result, continuous DNN inference cannot be guaranteed on such systems, especially under severe power constraints resulting from small battery capacities and solar panel sizes. A promising approach to dynamically adjust the power consumption of DNN inference are early-exit neural networks (EE-NNs), that allow a DNN to exit early at different points during its inference. In this paper, we propose a simulation-aided neural architecture search framework to explore EE-DNN architectures (EENAS) and an online energy manager (EM) that dynamically decides which early exit to take based on the available energy and the EE-NN’s confidence in its predictions while ensuring energyneutral operation (ENO). We evaluate our approach on four vision datasets and show not only that our EENAS approach can find EE-NNs with low energy consumption that maintain a high accuracy, but also that our proposed EM can execute the explored EE-NNs with an up to 36 % improved accuracy compared to the state-of-the-art while satisfying the ENO constraints.
Recommended citation: Sixdenier, P., Deutel, M., & Teich, J. (2025). Early-Exit Neural Architecture Search for Energy-Harvesting Edge Computing. IEEE 18th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC).
Download Paper | Download Paper (open)
Unsupervised Learning of Variational Autoencoders on Cortex-M Microcontrollers
Published in IEEE 18th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), 2025
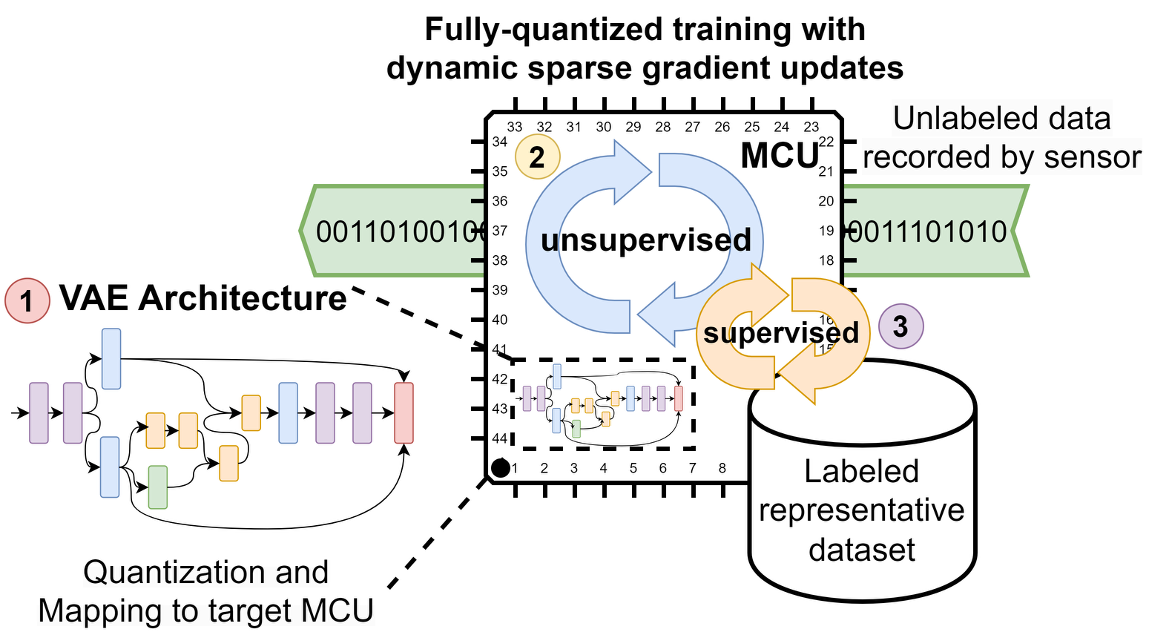
Training and fine-tuning deep neural networks (DNNs) to adapt to new and unseen data at the edge has recently attracted considerable research interest. However, most work to date has focused on supervised learning of pre-trained, quantized DNNs. Although these proposed techniques are advantageous in enabling DNN training even on resource-constrained devices such as microcontroller units (MCUs), they do not address the issue that large amounts of labeled data are required to perform supervised training. Moreover, while data are readily available at the edge, ground-truth labels are typically not. In this work, we explore variational autoencoders as a way to train unsupervised, i.e., without labels, feature extractors for image classification on a Cortex-M MCU. Using these feature extractors, we then train classification heads using small labeled representative sets of data to solve classification tasks. Our approach significantly reduces the amount of labeled data required, while enabling full DNN training from scratch on resource-constrained devices.
Recommended citation: Deutel, M., Plinge, A., Seuß, D., Mutschler, C., Hannig, F., & Teich, J. (2025). Unsupervised Learning of Variational Autoencoders on Cortex-M Microcontrollers. IEEE 18th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC).
Download Paper | Download Paper (open) | Download Slides
Recent Trends in Edge AI: Efficient Design, Training and Deployment of Machine Learning Models
Published in Charting the Intelligence Frontiers – Edge AI Systems Nexus, 2026
With a rising demand for ubiquitous smart systems, processing and interpreting large quantities of data generated on the edge at a high velocity is becoming an increasingly important challenge. Machine learning (ML) models such as Deep Neural Networks (DNNs) are an essential tool of today’s artificial intelligence due to their ability to make accurate predictions given complex tasks and environments. However, Deep Learning is computationally complex and energy intensive. This seems to contradict the characteristics of many edge devices, which have only limited memory, computational resources, and energy budget available. To overcome this challenge, an efficient ML model design is crucial that incorporates available optimization techniques from hardware, software, and methodological perspective to enable energy-efficient deployment and operation on the edge. This work comprehensively summarizes recent techniques for training, optimizing, and deploying ML models targeting edge devices. We discuss different strategies for finding deployable ML models, scalable DNN architectures, neural architecture search, and multi-objective optimization approaches, to enable feasible trade-offs considering available resources and latency. Furthermore, we give insight into DNN compression methods such as quantization and pruning. We conclude by investigating different forms of cascaded processing, from simple multi-level approaches to highly branched compute graphs and early-exit DNNs.
Recommended citation: Deutel, M., Mallah M., Wissing J., Scheele, S. (2026). Recent Trends in Edge AI: Efficient Design, Training and Deployment of Machine Learning Models. Charting the Intelligence Frontiers – Edge AI Systems Nexus.
Download Paper
PrototypeNAS: Rapid Design of Deep Neural Networks for Microcontroller Units
Published in arXiv preprint, 2026
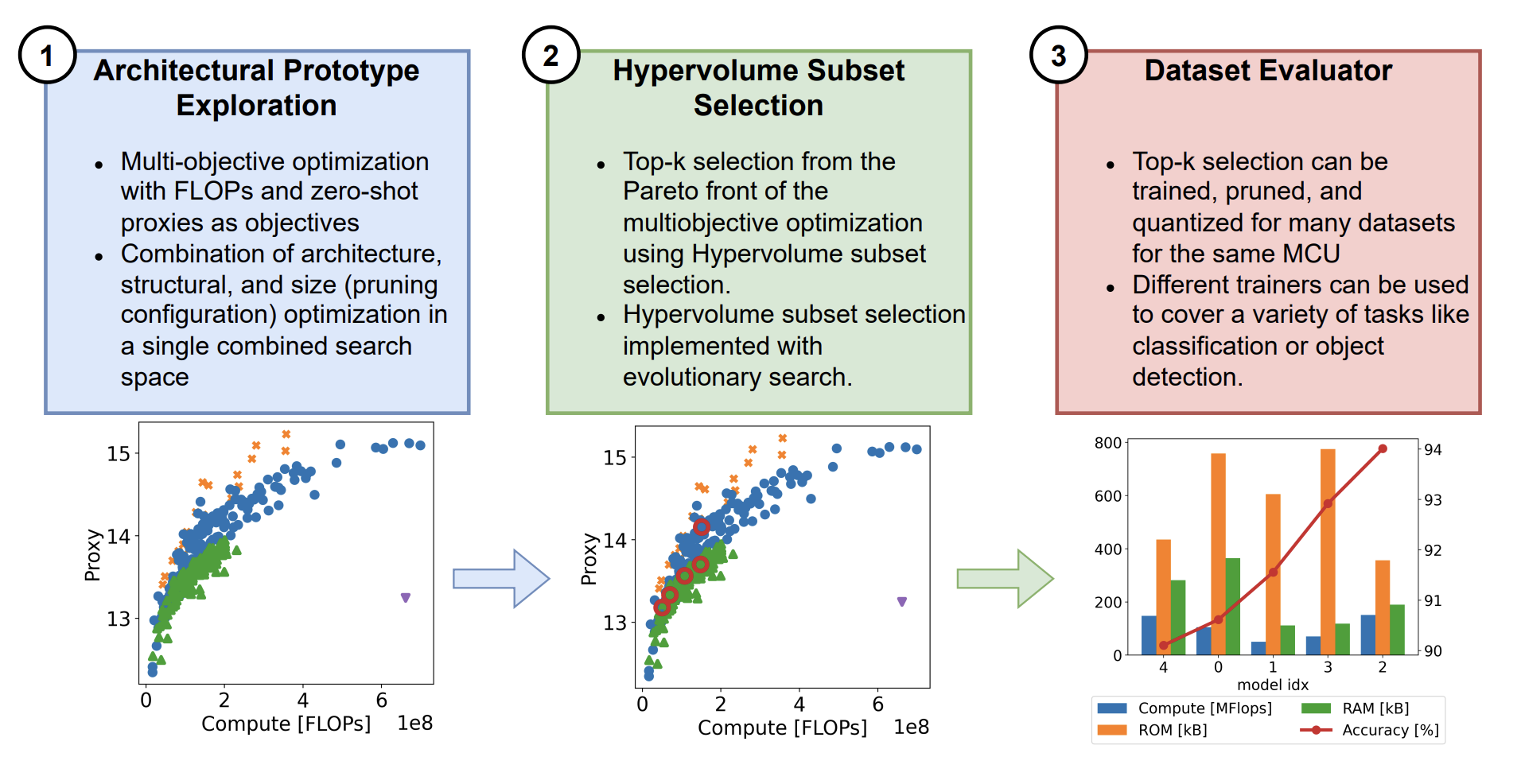
Enabling efficient deep neural network (DNN) inference on edge devices with different hardware constraints is a challenging task that typically requires DNN architectures to be specialized for each device separately. To avoid the huge manual effort, one can use neural architecture search (NAS). However, many existing NAS methods are resource-intensive and time-consuming because they require the training of many different DNNs from scratch. Furthermore, they do not take the resource constraints of the target system into account. To address these shortcomings, we propose PrototypeNAS, a zero-shot NAS method to accelerate and automate the selection, compression, and specialization of DNNs to different target microcontroller units (MCUs). We propose a novel three-step search method that decouples DNN design and specialization from DNN training for a given target platform. First, we present a novel search space that not only cuts out smaller DNNs from a single large architecture, but instead combines the structural optimization of multiple architecture types, as well as optimization of their pruning and quantization configurations. Second, we explore the use of an ensemble of zero-shot proxies during optimization instead of a single one. Third, we propose the use of Hypervolume subset selection to distill DNN architectures from the Pareto front of the multi-objective optimization that represent the most meaningful tradeoffs between accuracy and FLOPs. We evaluate the effectiveness of PrototypeNAS on 12 different datasets in three different tasks: image classification, time series classification, and object detection. Our results demonstrate that PrototypeNAS is able to identify DNN models within minutes that are small enough to be deployed on off-the-shelf MCUs and still achieve accuracies comparable to the performance of large DNN models.
Recommended citation: Deutel, M., Geis S., Plinge, A. (2026). PrototypeNAS: Rapid Design of Deep Neural Networks for Microcontroller Units. arXiv:2603.15106.
Download Paper
talks
Multi-Objective Bayesian Optimization of Deep Neural Networks for Deployment on Microcontrollers
Published:
This presentation discusses efficient design and deployment of DNNs on microcontroller units (MCUs) using both pruning and quantization techniques. It also provides an overview of automated hardware-aware DNN design for MCU targets using multi-objective Bayesian optimization.
More information | Slides
Optimizing Neural Networks with Multi Objective Bayesian Optimization and Augmented Random Search
Published:
This poster explores how multiobjective Bayesian optimization for hardware-aware neural architecture search for microcontroller targets can be improved with reinforcement learning, in particular Augmented Random Search (ARS).
More information | Poster
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
Published:
This poster shows how fully quantized DNNs deployed on Cortex-M microcontroller units (MCUs) can be either fine-tuned or even retrained from scratch. DNN training on MCUs poses additional challenges due to the tight resource constraints of such systems, and this poster discusses a methodology to overcome them.
More information | Poster
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
Published:
This talk discusses the potential of, as well as the technical challenges involved in, training fully quantized deep neural networks (DNNs) on Cortex-M microcontroller units (MCUs). First, the talk presents the additional challenges that arise due to the tight resource constraints and limited computing power of MCUs, as well as methods to overcome memory and computing constraints. Second, variational autoencoders are evaluated for their potential to train DNN classifiers unsupervised, i.e., without labels, and initial results are discussed.
More information | Slides
teaching
Exercise and Extended Exercise Grundlagen der Technischen Informatik
Undergraduate course, Friedrich-Alexander-Universität Erlangen-Nürnberg, Department Hardware-Software-Co-Design
This lecture deals with the implementation of algorithms in hard and software and the processing of data with the help of computers.
Multi-Core Architectures and Programming
Seminar, Friedrich-Alexander-Universität Erlangen-Nürnberg, Department Hardware-Software-Co-Design
Processors with multiple cores are already very widespread today. Examples of such architectures include modern graphics processors, which can consist of up to 4608 so-called streaming processors and 576 tensor computing units. Multi-core processors have a very high theoretical computing power and therefore open up fascinating new possibilities in scientific and other computationally intensive areas, such as multimedia applications, medical technology or finance. However, in order to fully exploit this performance, an efficient mapping of algorithms to the architecture of the respective multi-core processor must be found. Compared to traditional single-core processors, this often requires a radical rethink in programming. The aim of the seminar is to provide insights into state-of-the-art multi-core architectures, e.g. AI accelerators, and their programming paradigms. To gain practical development experience, NVIDIA TITAN RTX, Intel Neural Compute Sticks and Tegra AGX systems are offered, among others. The latest software development tools (TensorRT, OpenVINO, C++ 20, SYCL, CUDA, OpenCL, OpenMP + MPI) are available for project work in the team.