Published in Unlocking Artificial Intelligence pp 359 - 380, Springer Link, 2024
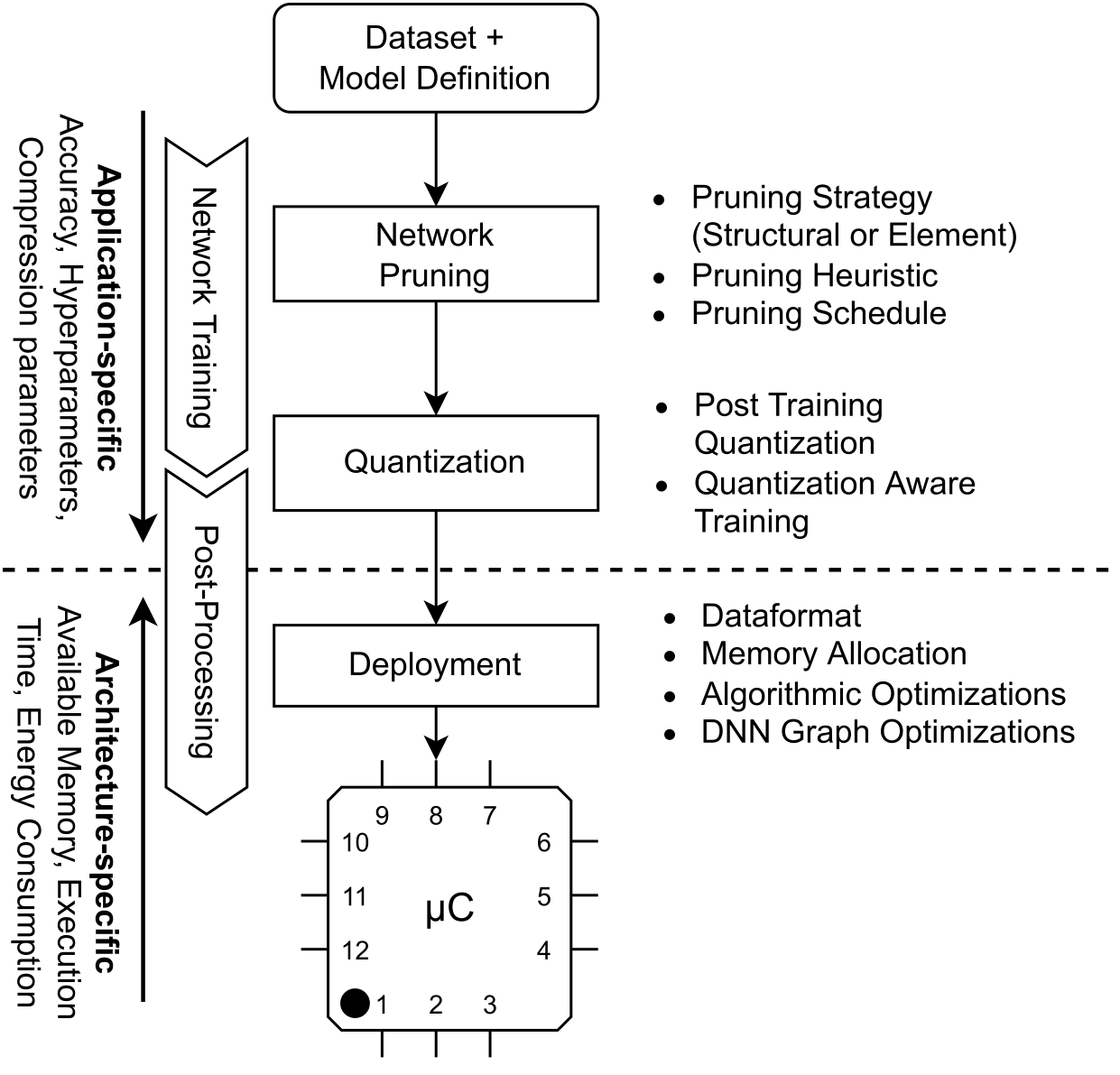
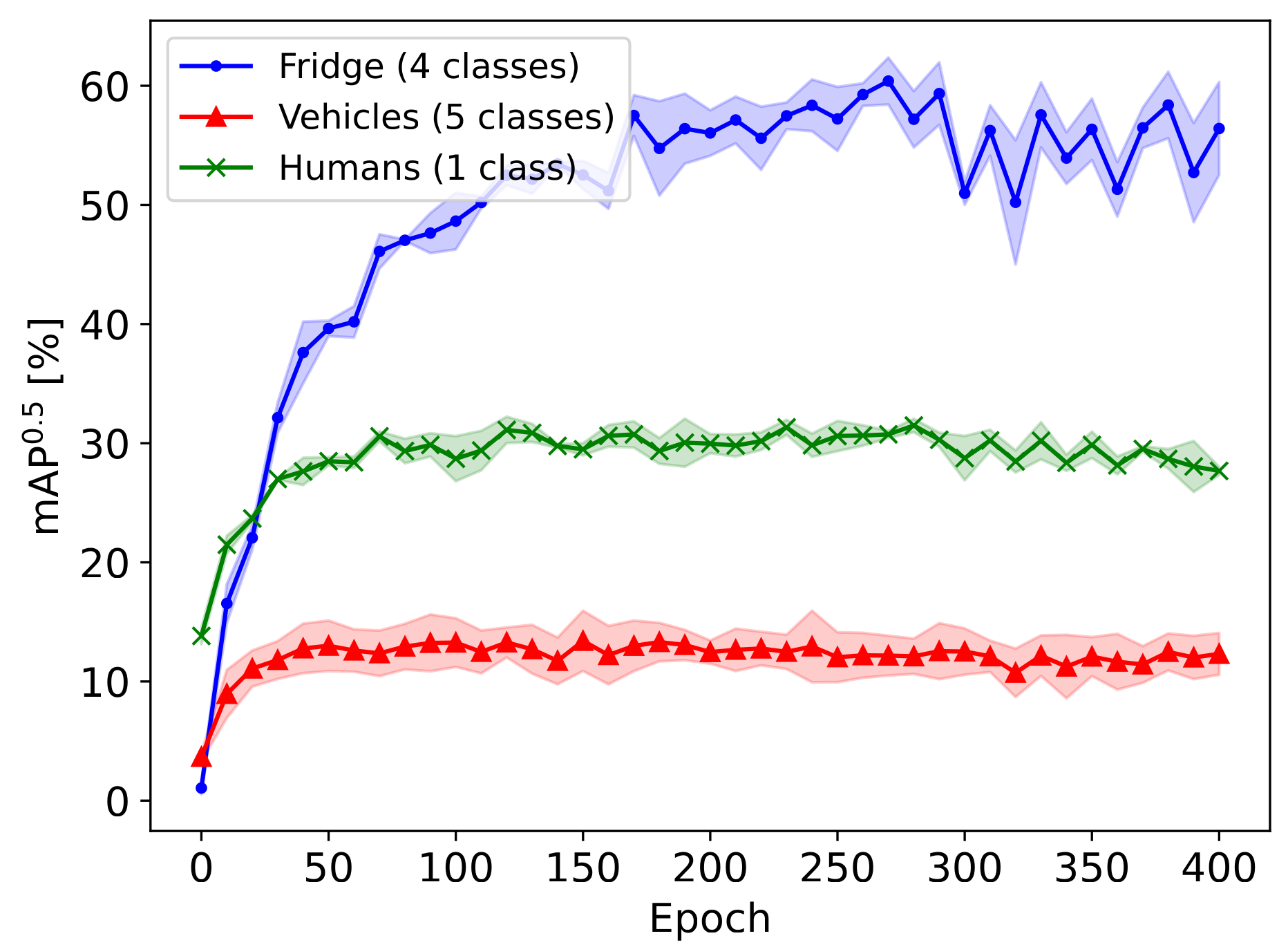
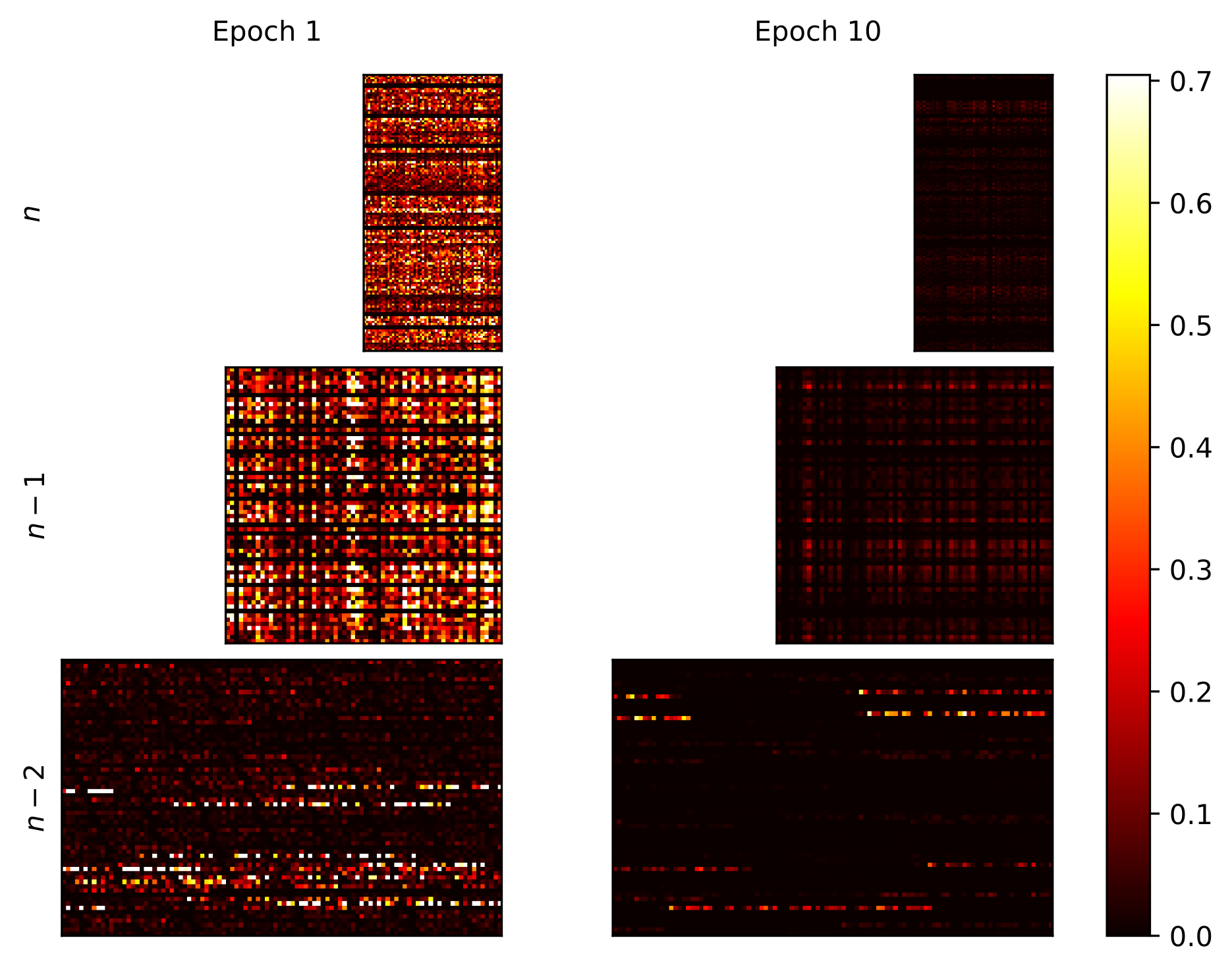
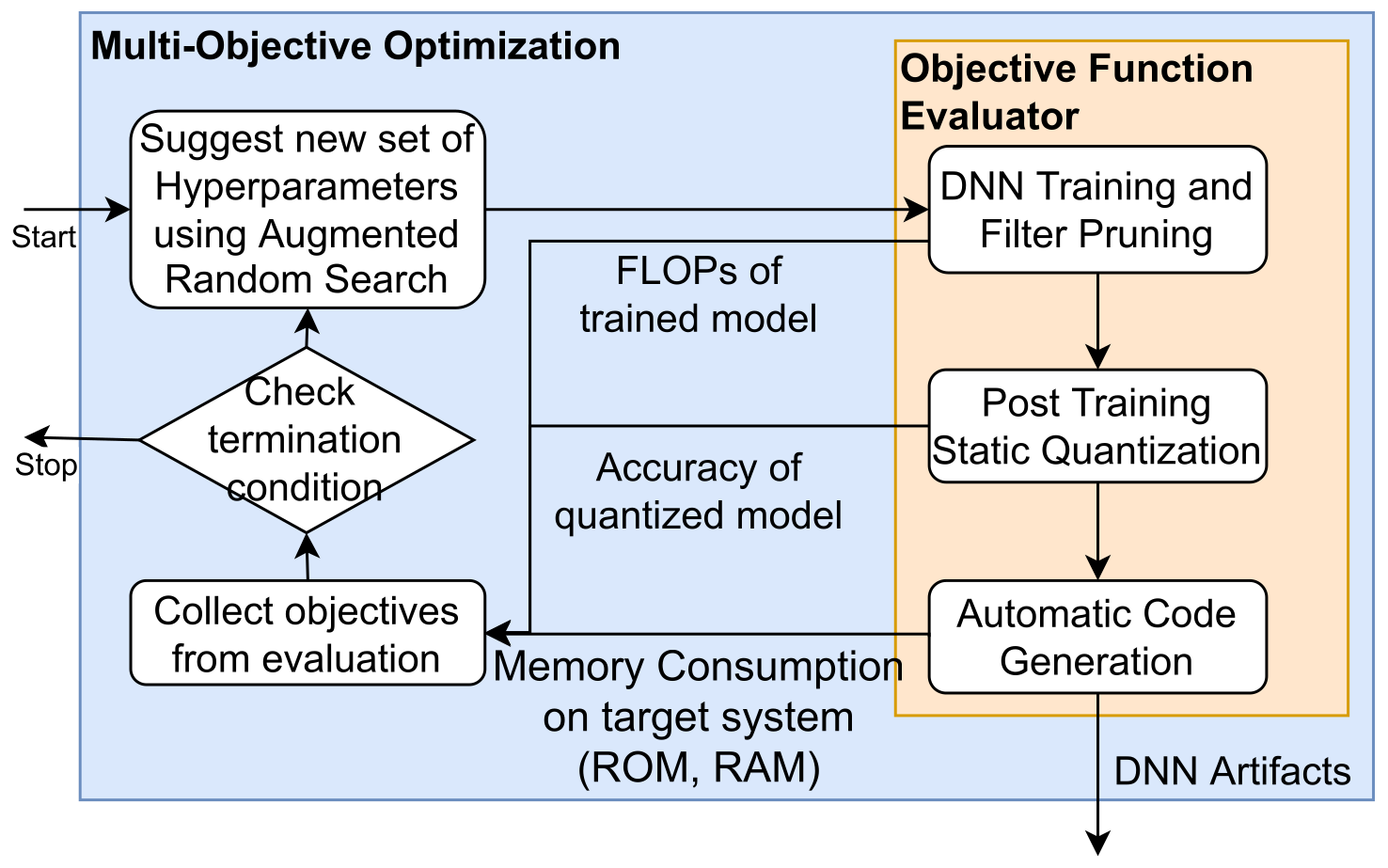
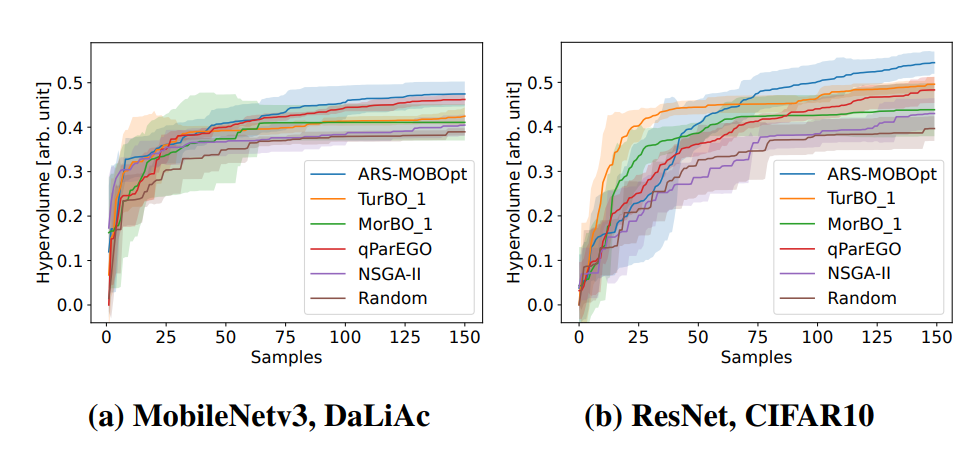
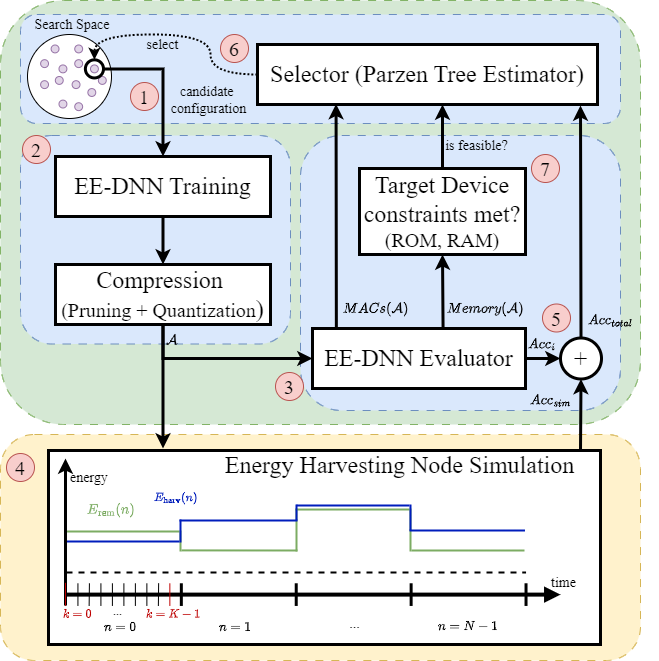
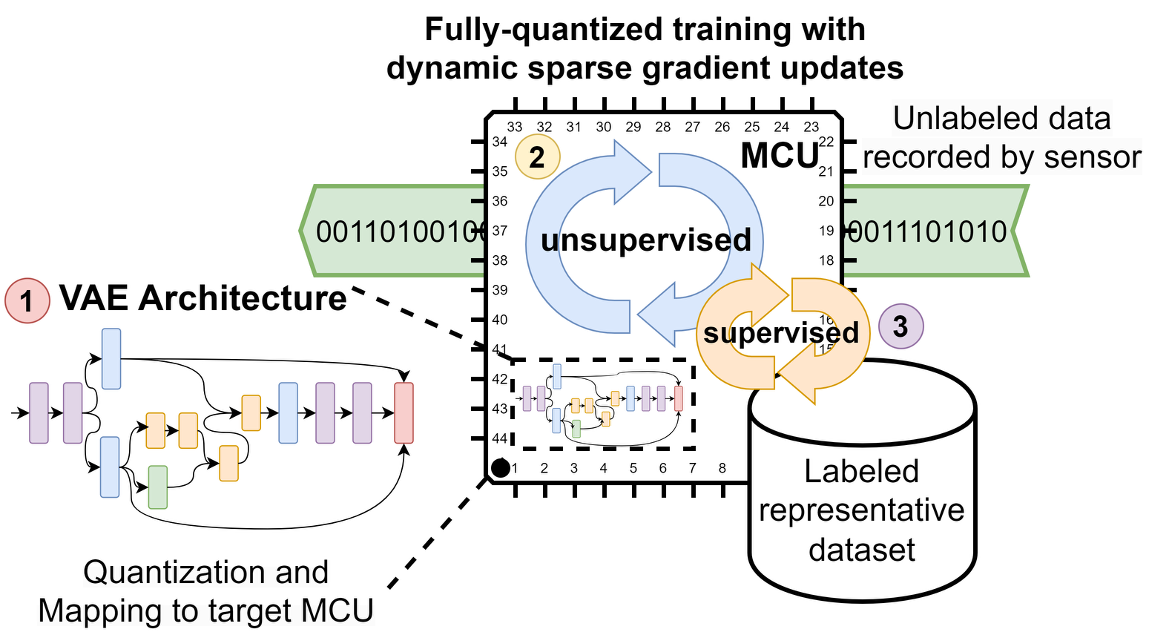
This chapter shows methods for the resource-optimized design of AI functionality for edge devices powered by microprocessors or microcontrollers. The goal is to identify Pareto-optimal solutions that satisfy both resource restrictions (energy and memory) and AI performance. To accelerate the design of energyefficient classical machine learning pipelines, an AutoML tool based on evolutionary algorithms is presented, which uses an energy prediction model from assembly instructions (prediction accuracy 3.1%) to integrate the energy demand into a multiobjective optimization approach. For the deployment of deep neural network-based AI models, deep compression methods are exploited in an efficient design space exploration technique based on reinforcement learning. The resulting DNNs can be executed with a self-developed runtime for embedded devices (dnnruntime), which is benchmarked using the MLPerf Tiny benchmark. The developed methods shall enable the fast development of AI functions for the edge by providing AutoML-like solutions for classical as well as for deep learning. The developed workflows shall narrow the gap between data scientist and hardware engineers to realize working applications. By iteratively applying the presented methods during the development process, edge AI systems could be realized with minimized project risks.
Recommended citation: Witt, N., Deutel, M., Schubert, J., Sobel, C., Woller, P. (2024). Energy-Efficient AI on the Edge. In: Mutschler, C., Münzenmayer, C., Uhlmann, N., Martin, A. (eds) Unlocking Artificial Intelligence. Springer, Cham.
Download Paper