Recent Trends in Edge AI: Efficient Design, Training and Deployment of Machine Learning Models
Published in Charting the Intelligence Frontiers – Edge AI Systems Nexus, 2026
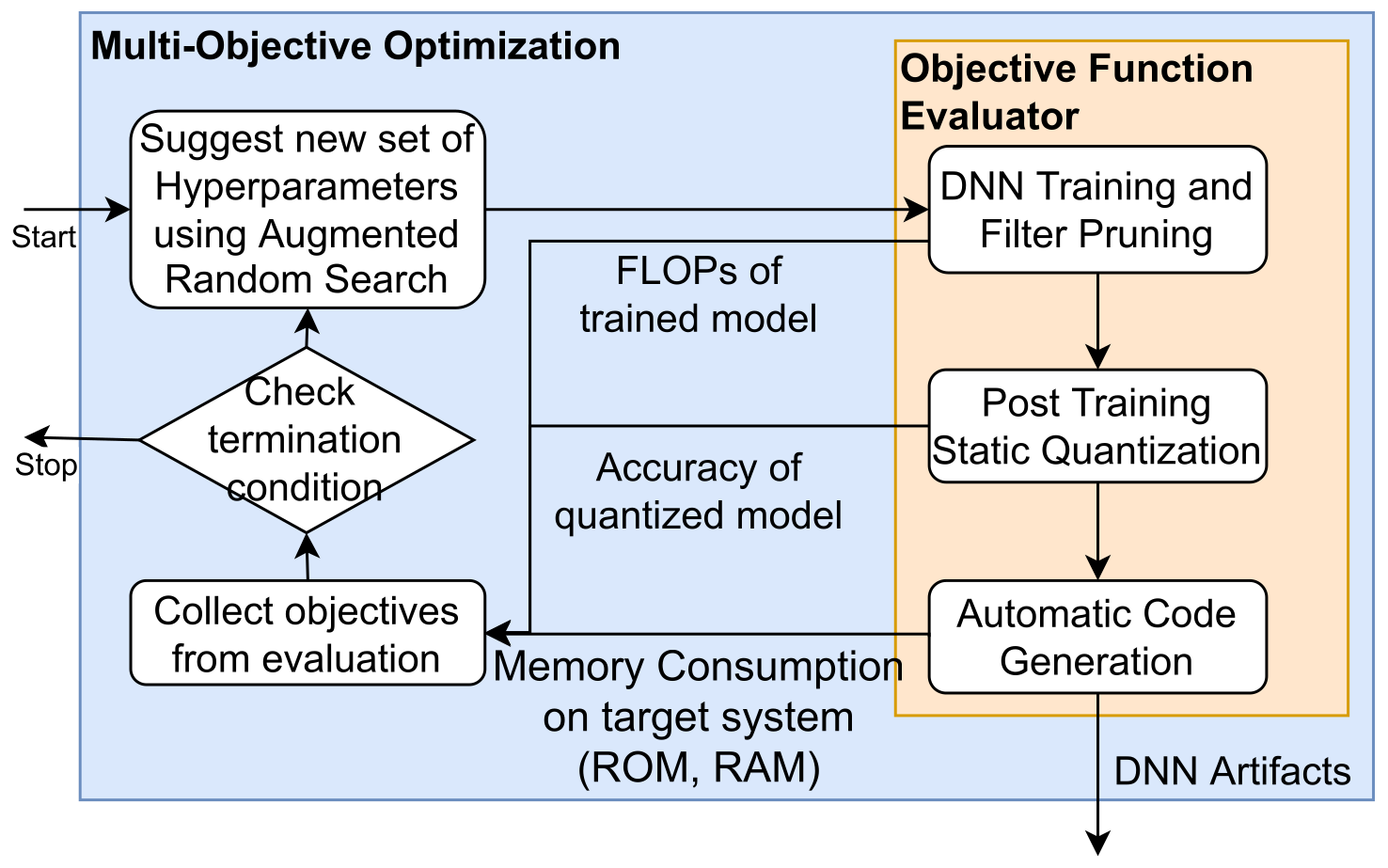
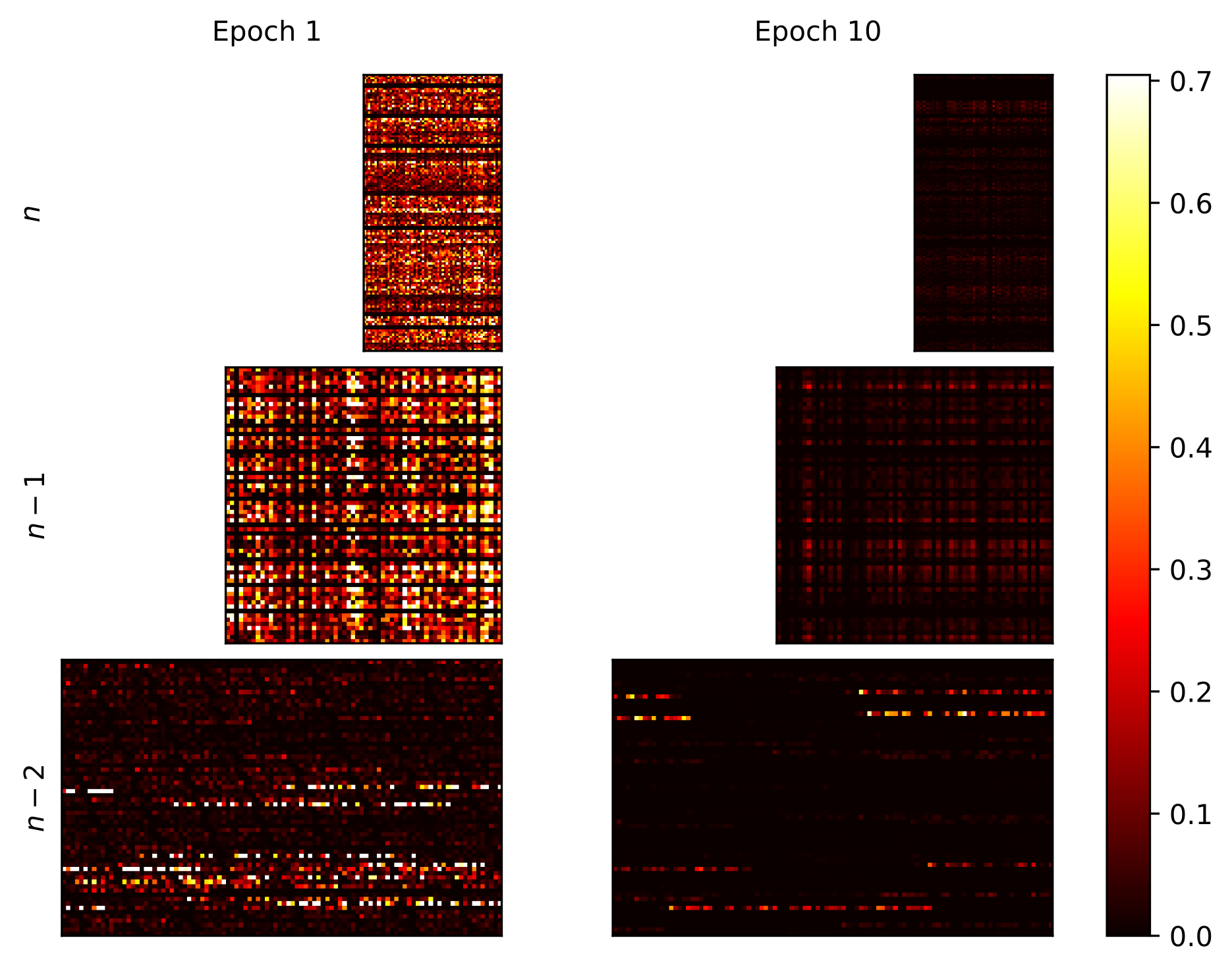
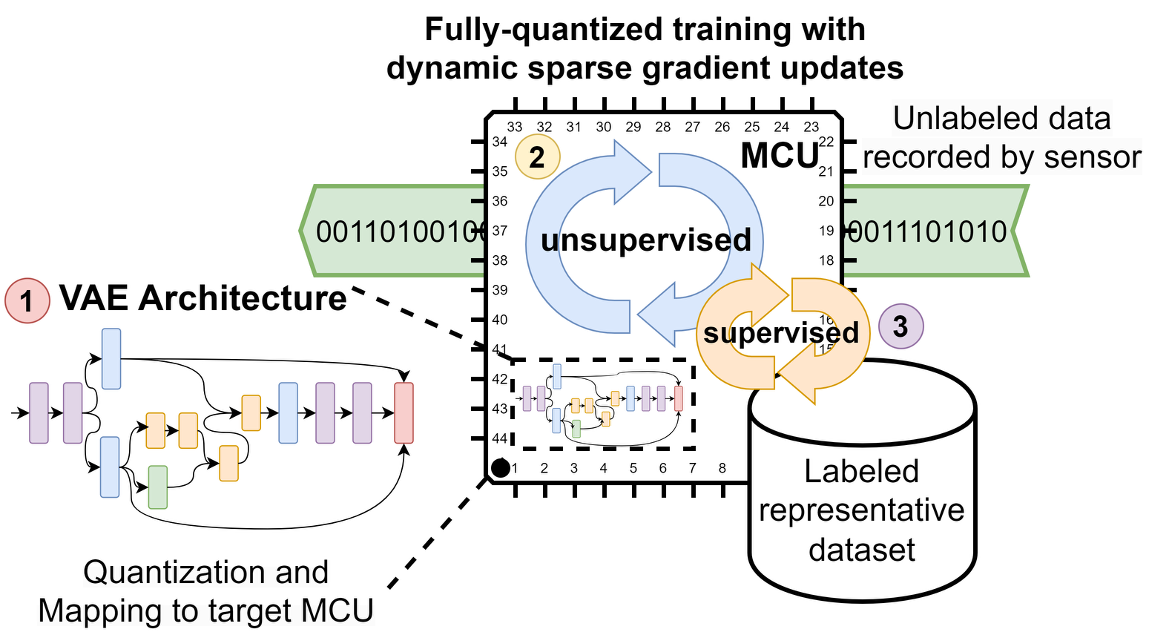
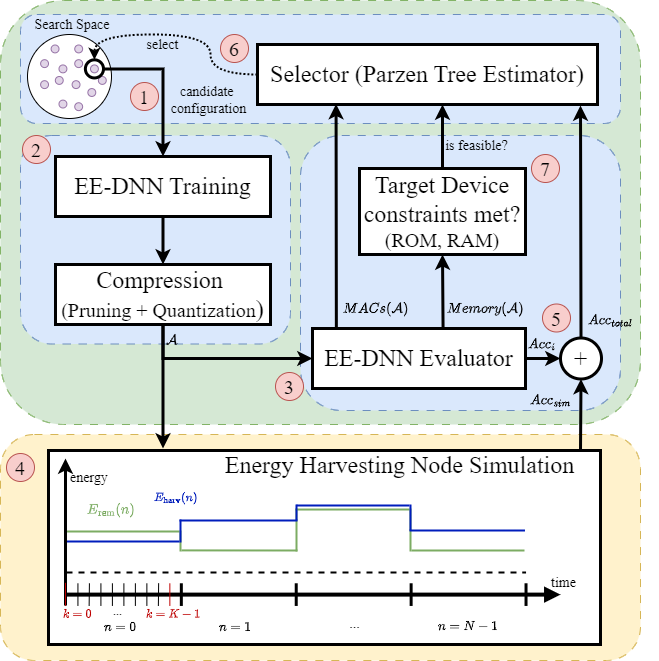
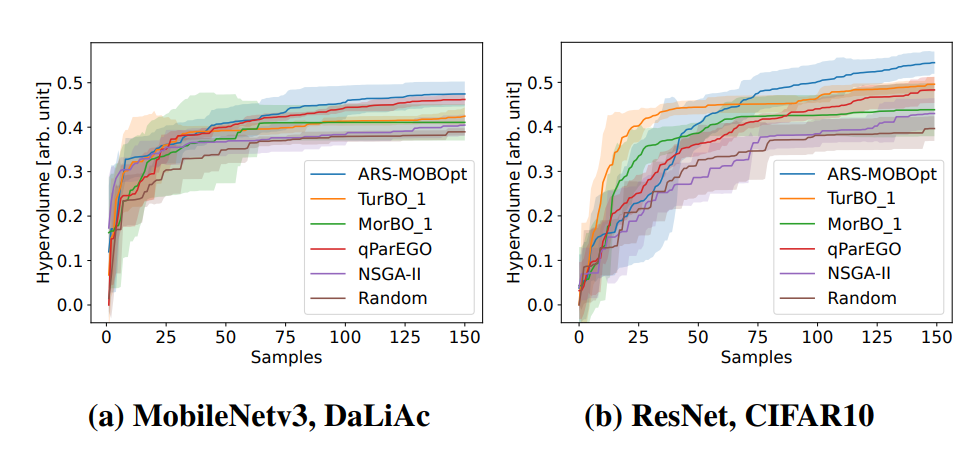
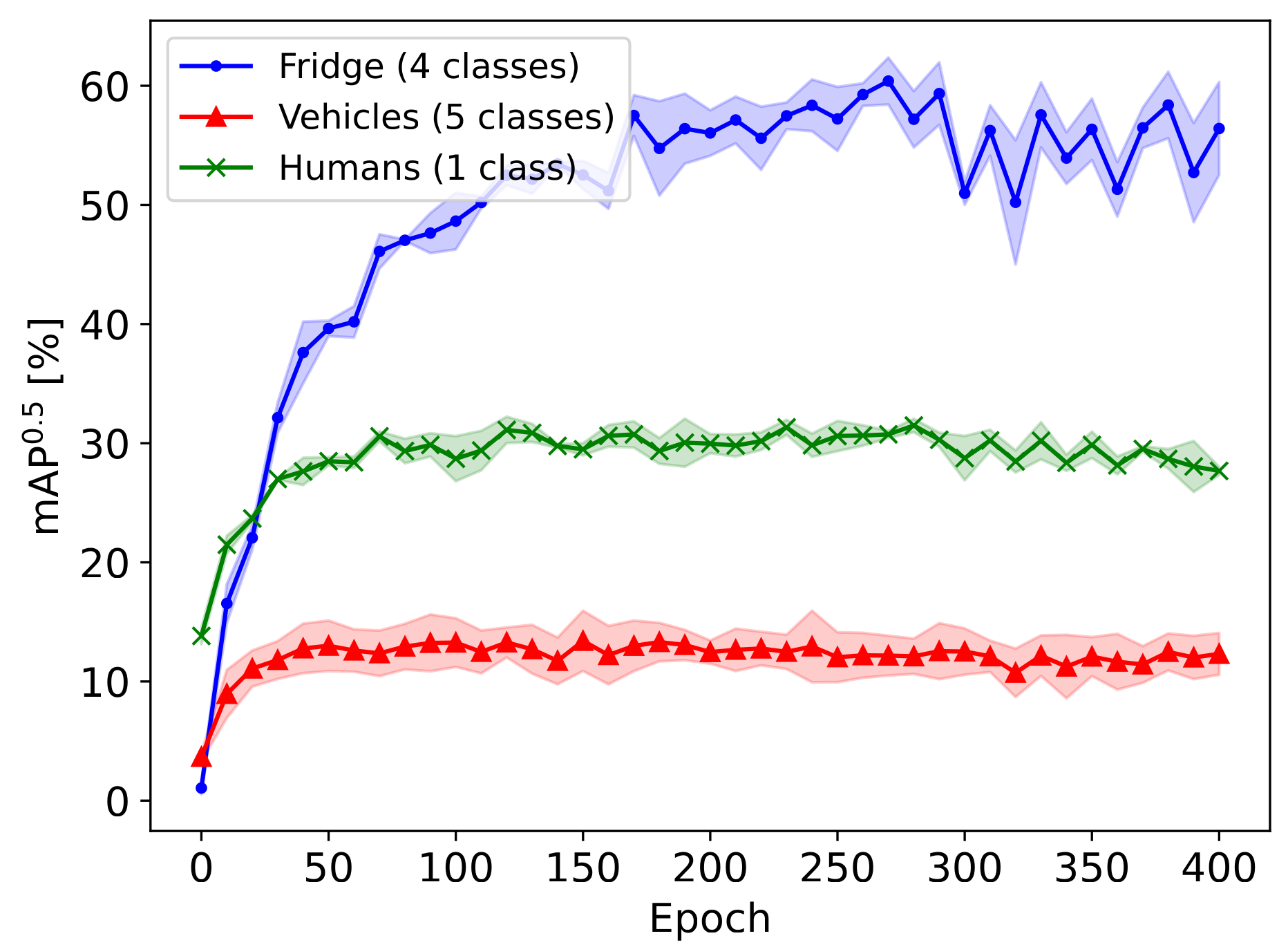
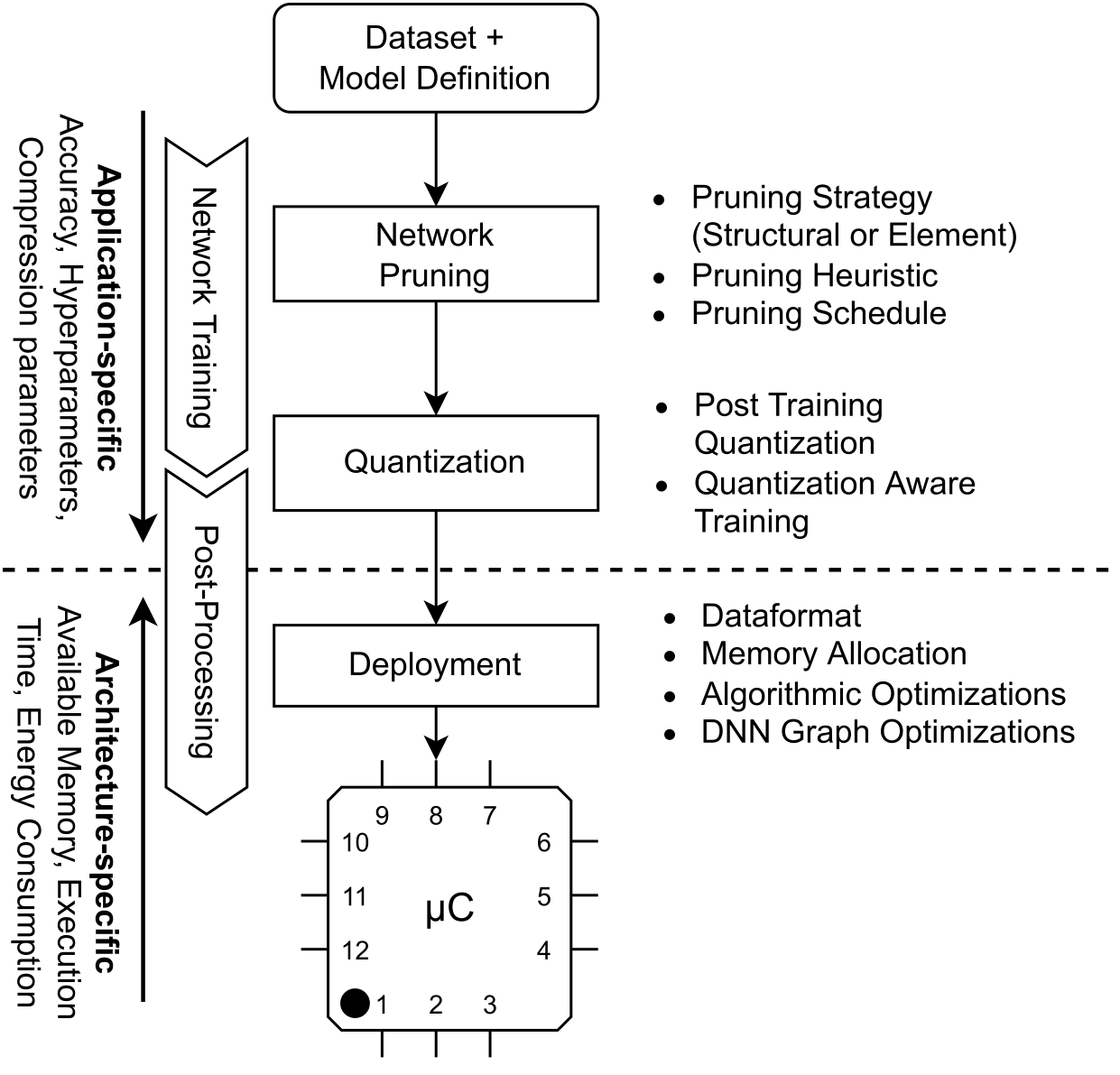
With a rising demand for ubiquitous smart systems, processing and interpreting large quantities of data generated on the edge at a high velocity is becoming an increasingly important challenge. Machine learning (ML) models such as Deep Neural Networks (DNNs) are an essential tool of today’s artificial intelligence due to their ability to make accurate predictions given complex tasks and environments. However, Deep Learning is computationally complex and energy intensive. This seems to contradict the characteristics of many edge devices, which have only limited memory, computational resources, and energy budget available. To overcome this challenge, an efficient ML model design is crucial that incorporates available optimization techniques from hardware, software, and methodological perspective to enable energy-efficient deployment and operation on the edge. This work comprehensively summarizes recent techniques for training, optimizing, and deploying ML models targeting edge devices. We discuss different strategies for finding deployable ML models, scalable DNN architectures, neural architecture search, and multi-objective optimization approaches, to enable feasible trade-offs considering available resources and latency. Furthermore, we give insight into DNN compression methods such as quantization and pruning. We conclude by investigating different forms of cascaded processing, from simple multi-level approaches to highly branched compute graphs and early-exit DNNs.
Recommended citation: Deutel, M., Mallah M., Wissing J., Scheele, S. (2026). Recent Trends in Edge AI: Efficient Design, Training and Deployment of Machine Learning Models. Charting the Intelligence Frontiers – Edge AI Systems Nexus.
Download Paper